On the Robust Performance of the ST-RRED Video Quality Predictor
Al Bovik, Rajiv Soundararajan, and Christos Bampis
Background
Spatio-Temporal RRED (ST-RRED) is a video quality model that was developed in LIVE during 2013 as an example of a high performance reduced-reference picture quality model that delivered peak performance in terms of video quality prediction [1]. A basic design element of ST-RRED was that it be a flexible framework, that allowed for easy scaling in terms of image dimension, bitrate, and the amount of reference information required to conduct video quality prediction. In principle, ST-RRED can be implemented in forms ranging between and including the extremes of Full Reference and a Single-Number model, whereby either all of the reference video would be required, or any amount in between, down to a single number from each reference video frame.
Given that Reduced Reference (RR) VQA has proven to be rather a niche field, LIVE moved on to other pursuits, and ST-RRED moved under the radar for some time, although it has been well received and cited, and was accorded a best journal paper award in 2016 [2]. Free code for the single number and ``1/576" versions of ST-RRED (where 1/576th of the available reference video information is required) have been available at [3] since the algorithm was published.
Very recently, in extended experiments, LIVE researchers have been re-exploring the usefulness of ST-RRED in extended research on video Quality-of-Experience, which encompasses extended video impairments such as bitrate variations and stalling events, and their effect on user satisfaction. The idea is to supplement video quality assessment models, like ST-RRED, with other information related to quantities such as the client buffer condition, available bandwidth, stall density, and so on.
We found that ST-RRED performed unusually well on such contents, substantially outperforming stalwart models such as Multi-scale SSIM. While ST-RRED is carefully defined in terms of well-understood perceptual principles, including highly regular statistical models of pictures, and may be viewed as a sophisticated elaboration of the classic Visual Information Fidelity (VIF) model [4], we were still somewhat surprised by how well ST-RRED was able to accurately predict perceptual motion picture quality in support of broader QoE measurements.
Our curiosities heightened, we decided to more rigorously test ST-RRED against a broader swathe of video quality databases then we had done when the model was first published. Towards this we simply used the publicly-available 1/576 version of ST-RRED, and tested it on a wide variety of public-domain subjective picture quality databases.
Performance
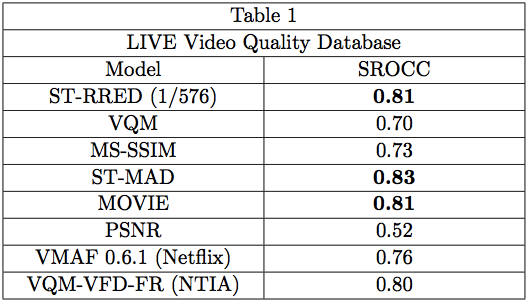
Of course, we already had available results on the LIVE Video Quality Assessment Database (LIVE VQA) [5, 6], which are shown (SROCC only, for simplicity; in all the following where scores were available, LCC scores followed similar relative trends) in Table 1 below. In the Table, ST-RRED (1/576) refers to the ST-RRED model described in [1], and available as code in [3], which uses 1 of every 576 pieces of available reference information to conduct VQA. VQM refers to the ITU standard model in [7], Multi-scale SSIM (MS-SSIM), which is marketed and implemented globally by the post-production, broadcast, cable, and satellite Television industry [8], the MOVIE index [9], which is also marketed globally, the ST-MAD model [10], which builds on the IQA Most Apparent Distortion model, the venerable (but very poorly performing [11], despite the odd insistence of the video compression standards community on using it!) Peak-Signal-to-Noise Ratio (PSNR), the Open-Source (and hence evolving) Netflix Video Multimethod Assessment Fusion (VMAF 0.6.1) model [11], which (in current form) fuses VIF features with edge and motion features, and VQM-VFD-FR [12], which is an elaboration of VQM that seeks to handle rate changes, and was trained on many databases.
As the results show (note: we report results of other algorithms as published by their authors, when available), the 1/576 ST-RRED model ranks closely with top-performers ST-MAD and MOVIE, probably within, or close to statistical equivalence. However, 1/576 ST-RRED is a much more efficient model than either MOVIE or ST-MAD, both of which require highly compute-intensive optical flow calculations, while 1/576 ST-RRED makes no use of motion at all, instead only requiring measurements of natural video statistics on frame differences. Moreover, 1/576 ST-RRED can achieve further deep efficiency, since it is reduced reference, and comparisons need only be computed on a vastly reduced set of coefficients, meaning other coefficients and comparisons need not even be computed. It is very likely that a full-reference version of 1/576 ST-RRED would perform better, as we have observed monotonically-improving prediction power with increased reference information [1]. All factors considered, the performance of 1/576 ST-RRED is rather remarkable.
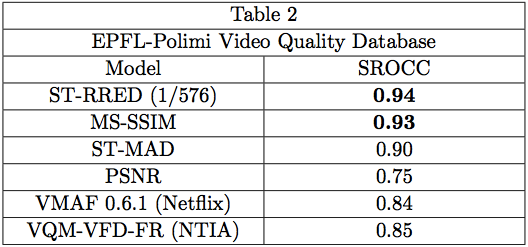
We also applied 1/576 ST-RRED on the EPFL-Polimi Dataset [13], which focuses only on compression artifacts. These results are shown in Table 2. Again, 1/576 ST-RRED performed surprisingly well, matched but not exceeded in performance only by MS-SSIM. Results for the other models are not available on this database.
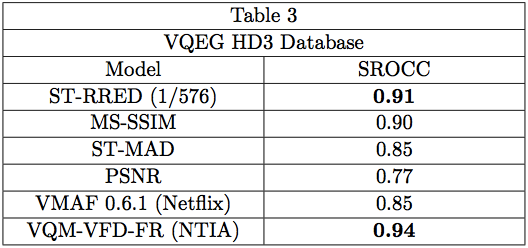
We also applied 1/576 ST-RRED on the VQEG HD3 Database, which unlike most VQEG databases, has some videos with associated subjective scores available. Again, 1/576 ST-RRED topped the results on this database, although it was edged in performance in this instance by VQM-VFD-FR. Unlike VQM-VFD-FR, 1/576 ST-RRED is very reduced reference, and moreover, uses no training process of any kind to attain highly competitive performance. Of course, ST-RRED is vastly more memory- efficient than VQM-VFD-FR.
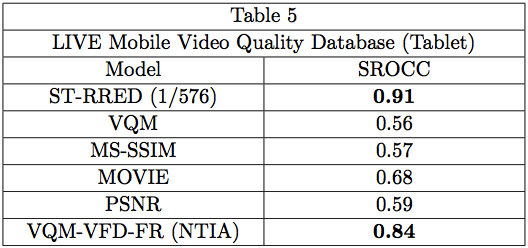
The simple temporal structure of the entire suite of ST-RRED models enables it to be a simple, effective VQA tool to achieve efficient predictions of motion picture Quality of Experience, which encompasses not only picture quality, as affected by spatio-temporal distortions, but also changes, often large, in picture quality over time (arising from, for example, changes in bitrate caused by channel conditions, or switching between cloud-based video encoding ladders). The LIVE Mobile Video Quality Database (``LIVE Mobile") [14, 15], was the first of a series of public-domain subjective picture quality databases that we have designed to measure various aspects of QoE. We ran ST-RRED on the two sub-databases of LIVE Mobile, which unlike LIVE VQA, strove to directly address the experience of viewing time-varying distorted videos on mobile devices (smart phones and tablets). One sub-database presented distorted videos to human subjects on a tablet, and the other on a smartphone. The results are shown in Tables 4 and 5.
Table 4 shows the very remarkable performance of the 1/576 RRED model on the ``Smartphone" sub-database, as it easily out-distances all of the other models, other than VMAF 0.6.1, which is closely matched by ST-RRED. In fact, on those databases described thus far, the performance of ST-RRED and VMAF 0.6.1 has usually been similar; this is not surprising, since VMAF 0.6.1 uses VIF-based natural scene statistic (NSS) features at its core, similar to ST-RRED; VMAF 0.6.1 uses a temporal frame-difference measure, whereas ST-RRED measures the NSS of frame-differences; and VMAF 0.6.1 uses a measure of detail quality [16], while ST-RRED applies perceptual weights emphasizing detail sub-bands in the quality prediction process [1].
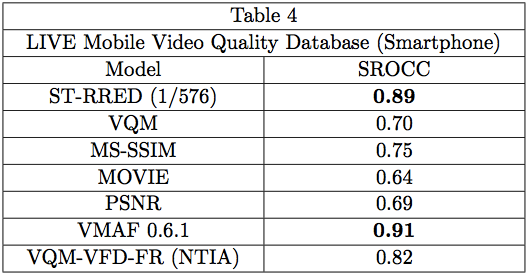
Table 5 shows model performance on the ``Tablet" sub-database of LIVE Mobile; again, 1/576 ST-RRED delivers very outstanding performance. Data is not available for VMAF 0.6.1 and ST-MAD on this database, but one would expect similarly consistent performance.
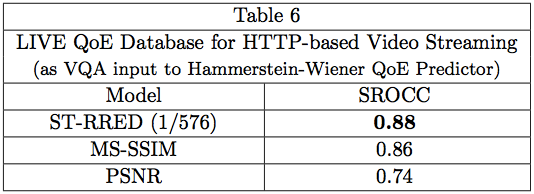
Another, more recent database directed towards QoE measurement tools is the LIVE QoE Database for HTTP-based Video Streaming [17, 18]. What makes this database different in regards to VQA model comparison, is that the tested models are not applied in isolation, but are instead input into a Hammerstein-Wiener system identification model, which learns to conduct perceptual QoE in the presence of HTTP-based rate changes, using an associated database including human behavioral scores. The number of tested models is therefore limited, as shown in Table 6. When used in this context, 1/576 ST-RRED again delivered the best performance amongst the compared models.
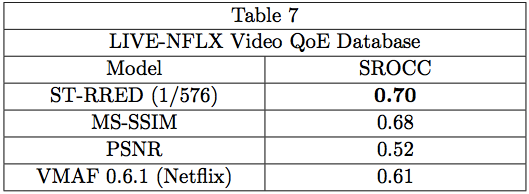
Lastly, we tested ST-RRED on a very recent database, called the LIVE-NFLX QoE Database [19, 20], representing an effort between LIVE and the video team at Netflix. This database makes a deeper exploration of QoE, by including models of stalling (rebuffering) patterns, as well as significant changes in bitrate, and by using real Netflix content. Like the above database, the VQA models are used as inputs to a learner, along with, in this instance, other inputs that are indicative of stalls. The goal of this work is ultimately to be able to make bitrate decisions that optimize QoE as a balance between picture distortion (from compression) against the likelihood of stalls. Here, Table 7 shows the results on videos containing diverse Netflix content, bitrate variations, and various stalling patterns that are assessed. Once again, 1/576 ST-RRED handily outperforms the other models, especially when used in the QoE framework where both bit rate changes and stalls are considered.
Computational Complexity
While ST-RRED is far more compute efficient than VQA models such as ST-MAD and MOVIE, it still calculates a full multi-scale multi-orientation steerable filtering decomposition. However, even this much computation is not necessary. In its original software release, ST-RRED uses only one scale and orientation of the full steerable decomposition. Therefore, it is possible to further optimize the compute time, by only calculating the desired sub-band, without any loss of the quality prediction power. We have found that the optimized version of ST-RRED delivers a 10 fold improvement in compute time [21]. We make this optimized implementation of ST-RRED publicly available in [22]. As an alternative, we have also recently created SpEED-QA [21], a spatial domain counterpart of ST-RRED for image and video quality assessment, which is even more efficient. Notably, SpEED-QA is approximately 70 times faster than ST-RRED and 7 times faster than the optimized version, at the cost of only a very small performance degradation.Summary
Overall, the reduced reference 1/576 ST-RRED video quality prediction model achieves uniformly standout performance on a wide variety of video quality databases, despite its conceptual and computational simplicity, and the fact that it can greatly reduce the amount of reference comparison or computation that is required. In this analysis, we have only used information that is already available in other published work, with the exception of the new 1/576 ST-RRED results. As such, ST-RRED is quite appealing as a much faster, higher performing model than other video quality prediction models. Naturally we are open to opinions and comments (for example if we have left out any really relevant results). We are also exploring theoretical, practical, and market applications of ST-RRED. Feel free to email me at bovik@ece.utexas.edu.
References
[1] R. Soundararajan and A.C. Bovik, “Video quality assessment by reduced reference spatio-temporal entropic differencing,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 23, no. 4, pp. 684-694, April 2013.
[2] IEEE Circuits and Systems for Video Technology Best Paper Award, 2016.
[4] H.R. Sheikh and A.C. Bovik, “Image information and visual quality,” IEEE Transactions on Image Processing, vol. 15, no. 2, pp. 430-444, February 2006.
[5] K. Seshadrinathan, R. Soundararajan, A.C. Bovik and L.K. Cormack, “Study of subjective and objective quality assessment of video,” IEEE Transactions on Image Processing, vol. 19, no. 6, pp. 1427-1441, June 2010.
[6] K. Seshadrinathan, R. Soundararajan, A.C. Bovik and L.K. Cormack, “LIVE Video Quality Database,” Laboratory for Image and Video Engineering, 2009.
[7] M.H. Pinson and S. Wolf, “A new standardized method for objectively measuring video quality,” IEEE Transactions on Broadcasting, vol. 50, no. 3, pp. 312-322, September 2004.
[8] Z. Wang, E. Simoncelli and A.C. Bovik, “Multi-scale structural similarity for image quality assessment,” Thirty-Seventh Annual Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, California, November 9-12, 2003.
[9] K. Seshadrinathan and A.C. Bovik, “Motion-tuned spatio-temporal quality assessment of natural videos,” IEEE Transactions on Image Processing, vol. 19, no. 2, pp. 335-350, February 2010.
[10] P.T. Vu, C.V. Vu and D.M. Chandler, “A spatiotemporal most-apparent-distortion model for video quality assessment,” IEEE International Conference on Image Processing, Brussels, Belgium, September 11-14, 2011.
[11] Z. Li, A. Aaron, I. Katsavounidis, A. Moorthy and M. Manohara, “Toward a practical perceptual video quality metric,” Netflix Technical Blog, Monday, June 6, 2016.
[12] M.H. Pinson, L.K. Choi, and A.C. Bovik, “Temporal video quality model accounting for variable frame delay distortions,” IEEE Transactions on Broadcasting, vol. 60, no. 4, pp. 637-649, November 2014.
[13] F. De Simone, M. Tagliasacchi, M. Naccari, S. Tubaro, and T. Ebrahimi, “A H.264/AVC video database for the evaluation of quality metrics,” IEEE International Conference on Acoustics Speech and Signal Processing, Dallas, Texas, March 14-19, 2010.
[14] A.K. Moorthy, L.K. Choi, A.C. Bovik and G. de Veciana, “Video quality assessment on mobile devices: Subjective, behavioral, and objective studies,” IEEE Journal of Selected Topics in Signal Processing, Special Issue on New Subjective and Objective Methodologies for Audio and Visual Signal Processing, vol. 6, no. 6, pp. 652-671, October 2012.
[15] A.K. Moorthy, L.K. Choi, A.C. Bovik, and G. de Veciana, “LIVE Mobile Video Quality Database.”
[16] S. Li, F. Zhang, L. Ma, and K. Ngan, “Image quality assessment by separately evaluating detail losses and additive impairments,” IEEE Transactions on Multimedia, vol. 13, no. 5, pp. 935–949, Oct. 2011.
[17] C. Chen, L.K. Choi, G. de Veciana, C. Caramanis, R.W. Heath, Jr. and A.C. Bovik, “A model of the time-varying subjective quality of HTTP video streams with rate adaptations,” IEEE Transactions on Image Processing, vol. 23, no. 5, pp. 2206-2221, May 2014.
[18] C. Chen, L.K. Choi, G. de Veciana, C. Caramanis, R.W. Heath, Jr. and A.C. Bovik, “LIVE QoE Database for HTTP-based Video Streaming,” 2013.
[19] C. G. Bampis, Z. Li, A. K. Moorthy, I. Katsavounidis, A. Aaron, and A. C. Bovik, “Study of Temporal Effects on Subjective Video Quality of Experience,” IEEE Trans. Image Process., vol. 26, no. 11, pp. 5217–5231, 2017.
[20] C. G. Bampis, Z. Li, A. K. Moorthy, I. Katsavounidis, A. Aaron, and A. C. Bovik, “LIVE Netflix Video QoE Database,” 2017.
[21] C. G. Bampis, P. Gupta, R. Soundararajan and A. C. Bovik, “SpEED-QA: Spatial efficient entropic differencing for image and video quality,” IEEE Signal Process. Lett., vol. 24, no. 9, pp. 1333–1337, 2017.
[22] C. G. Bampis, P. Gupta, R. Soudararajan and A.C. Bovik, “Source code for optimized Spatio-Temporal Reduced Reference Entropy Differencing Video Quality Prediction Model,” 2017.