Image Information and Visual Quality
A Visual Information Fidelity measure for image quality assessment
Hamid R. Sheikh and Alan C. Bovik
Introduction
The field of digital image and video processing deals, in large part, with signals that are meant to convey reproductions of visual information for human consumption, and many image and video processing systems, such as those for acquisition, compression, restoration, enhancement and reproduction etc., operate solely on these visual reproductions. These systems typically involve tradeoffs between resources and the visual quality of the output. In order to make these tradeoffs we need a way of measuring the quality of images or videos that come from a system running under a given configuration. The obvious way of measuring quality is to solicit the opinion of human observers. However, such subjective evaluations are not only cumbersome and expensive, but they also cannot be incorporated into automatic systems that adjust themselves in real-time based on the feedback of output quality. The goal of quality assessment research is, therefore, to design algorithms for
objective
evaluation of quality in a way that is consistent with subjective human evaluation. Such QA methods would prove invaluable for testing, optimizing, bench-marking, and monitoring applications.
Traditionally, researchers have focused on measuring signal fidelity as a means of assessing visual quality. Signal fidelity is measured with respect to a reference signal that is assumed to have `perfect' quality. During the design or evaluation of a system, the reference signal is typically processed to yield a distorted (or test) image, which can then be compared against the reference using so-called
full reference
(FR) QA methods. Typically this comparison involves measuring the `distance' between the two signals in a perceptually meaningful way.
At LIVE, we have developed a novel information theoretic framework for image and video quality measurement that was based on natural scene statistics (NSS). Images and videos of the three dimensional visual environment come from a common class: the class of natural scenes. Natural scenes form a tiny subspace in the space of all possible signals, and researchers have developed sophisticated models to characterize these statistics. Most real-world distortion processes disturb these statistics and make the image or video signals
unnatural
. In [1], we proposed using NSS models in conjunction with a distortion (channel) model to quantify the information shared between the test and the reference images, and showed that this shared information is an aspect of fidelity that relates well with visual quality. In contrast to the HVS error-sensitivity and the structural approaches, the
statistical
approach, used in an information-theoretic setting, yielded an FR QA method that did not rely on any HVS or viewing geometry parameter, nor any constant requiring optimization, and yet was competitive with state of the art QA methods.
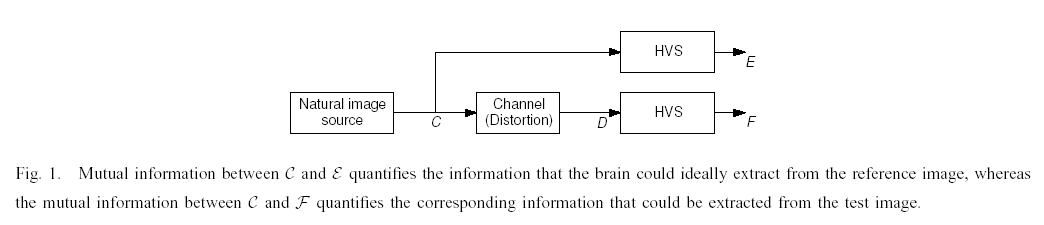
In [2] we extended the concept of information fidelity measurement for image quality assessment by proposing an image information measure, and explored the connections between image information and visual quality. Specifically, we modeled the reference image as being the output of a stochastic `natural' source that passes through the HVS channel and is processed later by the brain. We quantify the information content of the reference image as being the mutual information between the input and output of the HVS channel. This is the information that the brain could ideally extract from the output of the HVS. We then quantify the same measure in the presence of an image distortion channel that distorts the output of the natural source before it passes through the HVS channel, thereby measuring the information that the brain could ideally extract from the test image. This is shown pictorially in Figure 1. We then combine the two information measures to form a visual information fidelity measure that relates visual quality to
relative
image information.
VIF = Distorted Image Information / Reference Image Information (1)
Similarities with Human Visual System Based methods
VIF has interesting similarities with HVS based QA methods. In particular, the distorted image information (numerator of VIF) can be shown to be similar to a divisive-normalization based masking model for the HVS including channel decomposition and response exponentials. In [1], we have shown that the numerator of VIF is in fact an HVS based perceptual distortion metric (within additive and multiplicative constants) shown below.
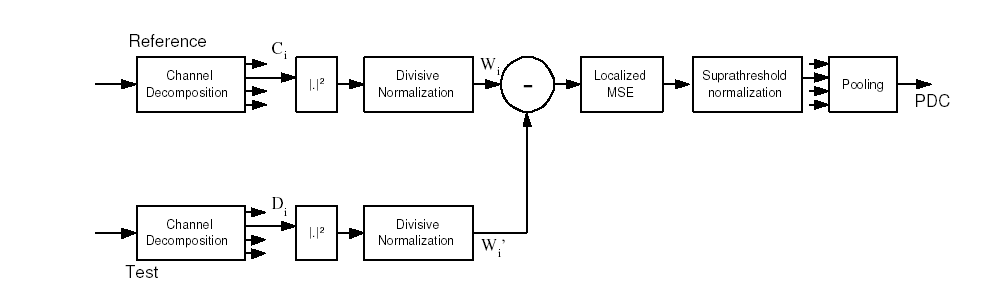
Figure 2
Following is a summary of the similarities and differences between the
numerator
of VIF and the perceptual distortion criterion of Figure 2 above.
-
A number of similarities are immediately evident: scale-space-orientation channel decomposition, response exponent, masking effect modeling, localized error pooling, suprathreshold effect modeling, and a final pooling into a quality score.
-
Some components of the HVS are not modeled in Figure2, such as the optical point spread function and the contrast sensitivity function.
-
The masking effect is modeled differently from some HVS based methods. While the divisive normalization mechanism for masking effect modeling has been employed by some QA methods most methods divisively normalize the signal with visibility thresholds that are dependent on neighborhood signal strength.
-
Minkowski error pooling occurs in two stages: first a localized pooling in the computation of the localized MSE (with exponent 2) and then a global pooling after the suprathreshold modeling with an exponent of unity. Thus the perceptual error calculation is different from most methods, in that it happens in two stages with suprathreshold effects in between.
-
In VIF, the non-linearity that maps the MSE to a suprathreshold-MSE is a logarithmic non-linearity and it maps the MSE to a suprathreshold distortion that is later pooled into a quality score. Some methods apply the supratreshold non-linearity
after
pooling, as if the suprathreshold effect only comes into play at the global quality judgement level. The formulation of VIF suggests that the suprathreshold modeling should come
before
a global pooling stage but after localized pooling, and that it affects visual quality at a
local
level.
-
We believe that a vector model for natural scene statistics allows us to model the linear dependencies between the subband coefficients. This dependence of perceptual quality on the correlation among coefficients is hard to investigate or model using HVS error sensitivities, but the task is greatly simplified by approaching the same problem with NSS modeling. Thus we feel that HVS based QA methods need to account for the fact that natural scenes are correlated within subbands, and that this inter-coefficient correlation in the reference signal affects human perception of quality.
-
Another significant difference between the dual of VIF and other HVS based methods is distinct modeling of signal attenuation. Other HVS based methods ignore signal gains and attenuations and treat all distortions as additive signal errors as well. In contrast, a generalized gain in the formulation of VIF ensures that signal gains are handled differently from additive noise components.
The normalization by reference image information in VIF (
denominator
of VIF) can be thought of as being a
content dependent adjustment
of HVS based methods. Specifically, after the HVS based methods compute the perceptual error strength, the annoyance factor of a particular perceptual error
strength may be different for different images, and thus may give a different impression of quality. We feel that the normalization by reference image information adjusts for this variation in image content.
VIF and improvement of visual quality
Note that VIF (in (1) above) is bounded below by zero since information is a non-negative quantity (assuming the reference image information is always positive), which indicates that all information about the reference image has been lost in the distortion channel. Also, in case the image is not distorted at all, and VIF is calculated between the reference image and its copy, VIF is
exactly
unity. Thus for all
practical distortion types, VIF will lie in the interval [0,1]. Thirdly, and this is where we feel that VIF has a distinction over traditional quality assessment methods, a linear contrast enhancement of the reference image that does not add noise to it will result in a VIF value
larger
than unity, thereby signifying that the enhanced image has a
superior
visual quality than the reference image! It is common observation that contrast enhancement of images increases their perceptual quality unless quantization, clipping, or display non-linearities add additional distortion. Theoretically, contrast enhancement results in a higher signal-to-noise ratio at the output of the HVS neurons, thereby allowing the brain to have a greater ability to discriminate objects present in the visual signal. The VIF is able to capture this improvement in visual quality.
While it is common experience that even linear point-wise contrast enhancement improves quality to a certain extent only, and that the quality starts deteriorating beyond a certain enhancement factor, we believe that in the real world, the perceived quality increases with contrast enhancement over many orders of magnitude. Illumination increase in the environment (which leads to an increases in the contrast of the light signals entering the eye as well, contrast being the signal that is encoded by the retina and sent to the brain) increases our perception of the quality of the perceived image over many orders of magnitude until the HVS neurons are driven to saturation. The effect of limited point-wise contrast improvement on a computer is therefore more an artifact of limited machine precision and display nonlinearities.
To the best of our knowledge, no other quality assessment algorithm has the ability to predict if the visual image quality has been enhanced by a contrast enhancement operation. We envision extending the notion of quantifying improvement in visual quality of images by image enhancement operations using a similar information-theoretic paradigm.
The pictures below show this property of VIF.

Reference VIF=1.0

Contrast enhanced. VIF=1.10

Blurred VIF=0.07

JPEG compressed VIF=0.10
Results and Comparisons with other methods
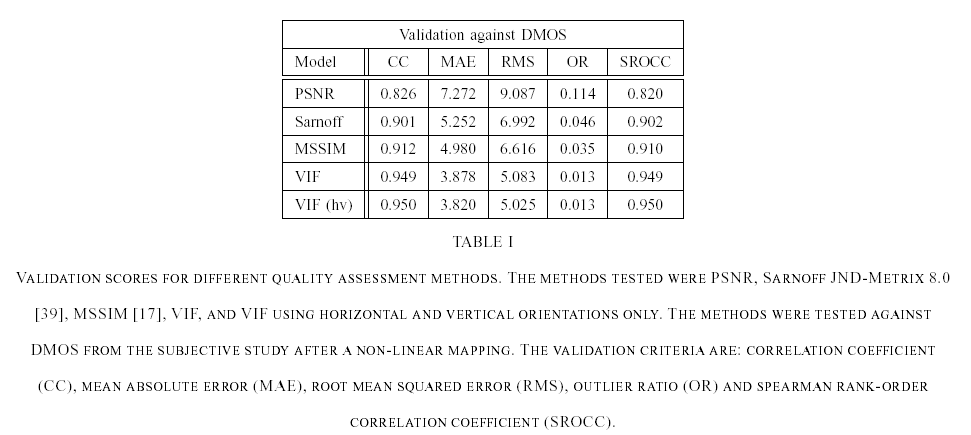
Here we compare the performance of VIF against PSNR, SSIM [3], and the well known Sarnoff model (Sarnoff JND-Metrix 8.0). The algorithms were validated using the
LIVE image quality assessment database Release 2
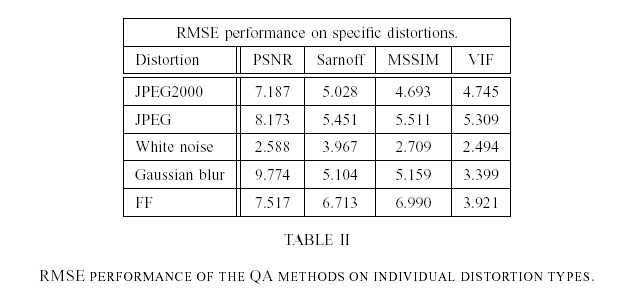
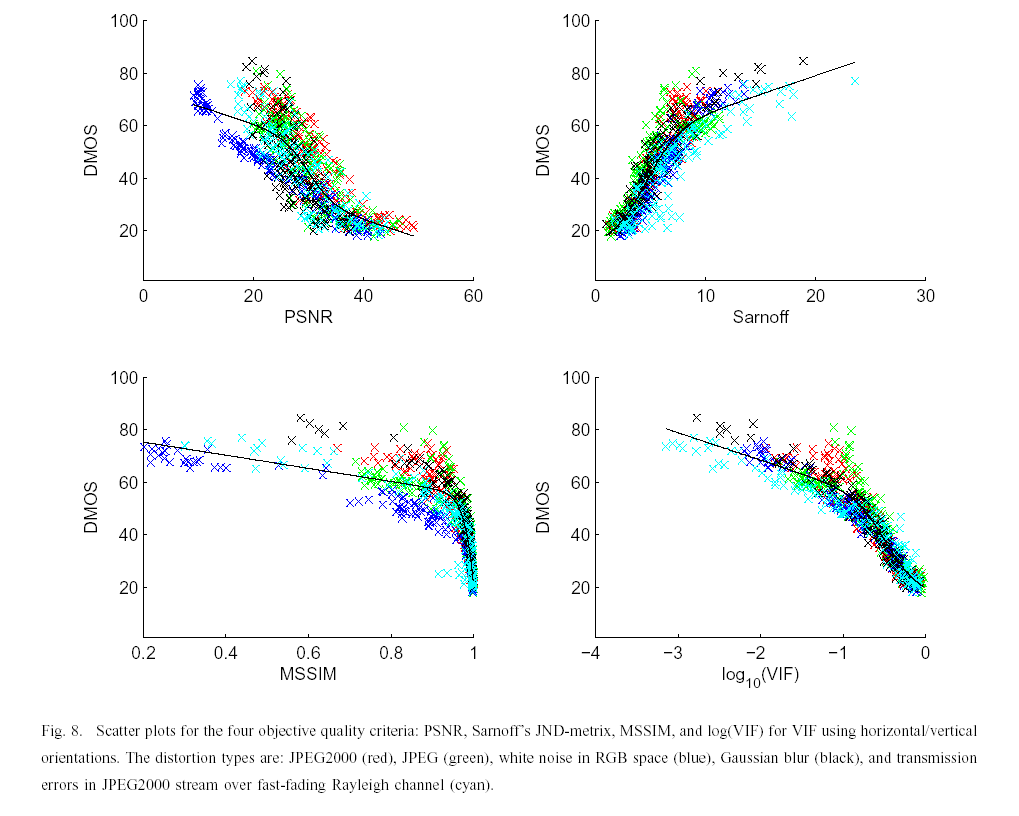
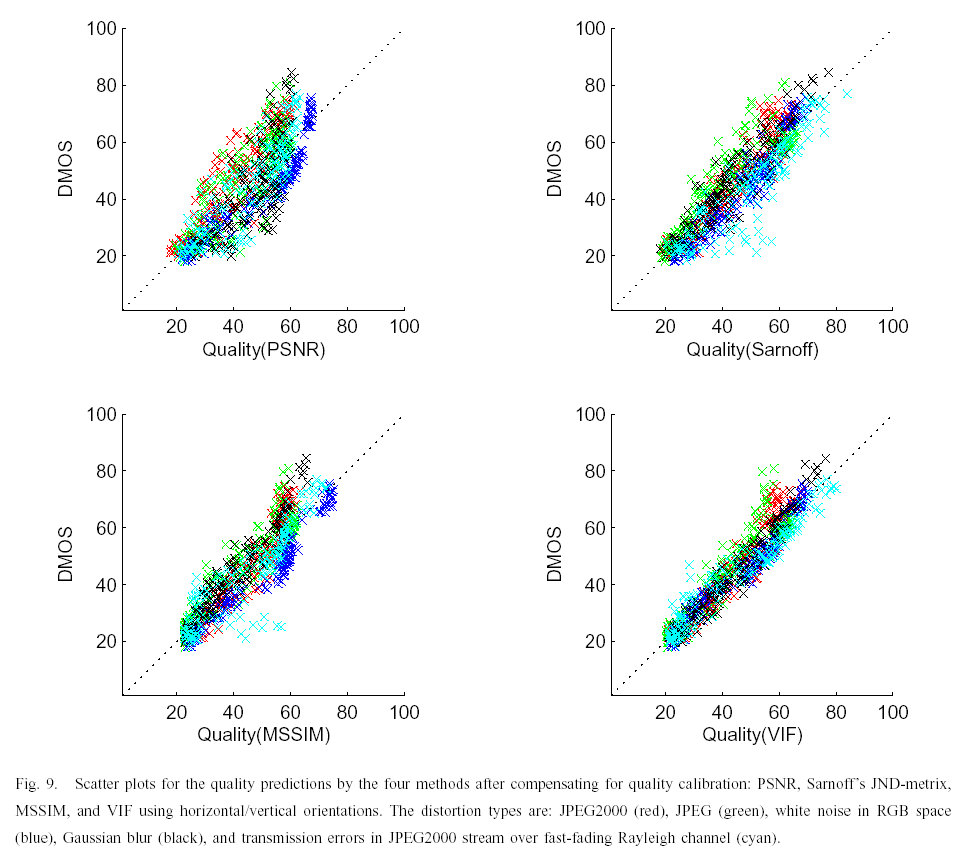
. Table I summarizes the results for the quality assessment methods. In Table II, we present the results of the algorithms when tested on individual distortion types. See [2] for more details. The scatter plots below show the fit of VIF against other methods before and after nonlinear regression.
Code
Note: If you download the code it is assumed that you agree to the
copyright notice
.
The code for Visual Information Fidelity [2], can be downloaded
here
.
A computationally simpler, multi-scale pixel domain implementation whose performance is slightly worse than the Wavelet domain version presented in [2] can also be downloaded
here
. The pixel domain version also uses a scalar Random Field model for natural images, instead of a vector version in [2]. There are advantages to using the VIF in the pixel domain as well as some disadvantages. The principle advantage is computational simplicity. Secondly, the Wavelet transform used in [2] is a highly overcomplete decomposition that adds a lot of linear correlation between coefficients. While the wavelet decomposition allows scale-space-orientation analysis, this makes the assumptions of conditional independence in [2] weaker. Pixel domain methods avoid this weakness of assumption, but do not allow orientation analysis.
Relevant Publications (download
here
)
[1] H.R. Sheikh, A.C. Bovik and G. de Veciana, "An information fidelity criterion for image quality assessment using natural scene statistics,"
IEEE Transactions on Image Processing
, vol.14, no.12, pp. 2117- 2128, Dec. 2005.
[2] H.R. Sheikh.and A.C. Bovik, "Image information and visual quality,"
IEEE Transactions on Image Processing
, vol.15, no.2,pp. 430- 444, Feb. 2006.
[3] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, "Image quality assessment: From error visibility to structural similarity,"
IEEE Transactions on Image Processing
, vol. 13, no. 4, Apr. 2004.
[4] H. R. Sheikh and A. C. Bovik , "A Visual Information Fidelity Approach to Video Quality Assessment" (Invited Paper), The First International Workshop on Video Processing and Quality Metrics for Consumer Electronics, Scottsdale, AZ, January 23-25, 2005.
[5] H.R. Sheikh, M.F. Sabir and A.C. Bovik, "A statistical evaluation of recent full reference image quality assessment algorithms",
IEEE Transactions on Image Processing
, vol.15, no.11, pp.3440-3451, Nov. 2006.
Please contact Dr. Hamid Rahim Sheikh (hamid dot sheikh at ieee dot org) if you have any questions.
This investigators on this research were:
Hamid Rahim Sheikh
--
Department of ECE
at
UT Austin
Dr. Alan C. Bovik
(
bovik@ece.utexas.edu
) --
Department of ECE
at
UT Austin
Back to Quality Assessment Research page